Block AI Crawlers
| 开发者 | lastsplash |
|---|---|
| 更新时间 | 2026年2月15日 21:47 |
| PHP版本: | 8.2 及以上 |
| WordPress版本: | 6.9 |
| 版权: | GPLv2 or later |
| 版权网址: | 版权信息 |
详情介绍:
Protect Your Content from AI Scraping
This plugin helps you prevent AI crawlers from using your content as training data for their products. By updating your site's
robots.txt, it blocks common AI crawlers and scrapers, aiming to protect your content from being used in the training of Large Language Models (LLMs).
Features
Blocks AI Crawlers
Includes:
- OpenAI - Blocks crawlers used for ChatGPT
- Google - Blocks crawlers used by Google's Gemini AI products
- Facebook / Meta - Used for Facebook's AI training
- Anthropic AI - Blocks crawlers used by Anthropic
- Perplexity - Block crawlers used by Perplexity
- Applebot - Blocks crawlers used by Apple
- ... and more!
- Download the plugin zip file.
- Go to your WordPress admin panel.
- Navigate to Plugins > Add New > Upload Plugin.
- Choose the zip file and click "Install Now."
- Activate the plugin.
robots.txt and add the necessary meta tags. No further configuration is required, but you can check the settings page for a full list of blocked crawlers.
Limitations
While this plugin aims to block specified crawlers, it cannot guarantee complete protection against all forms of scraping, as some bots may disregard robots.txt directives.
Support
For questions or support, please post on the forums or on GitHub.
安装:
- Activate the plugin through the 'Plugins' menu in WordPress
- Once installed the plugin is automatically activated. There are no user configured settings
- You can view more about what crawlers are being blocked at "Settings > Block AI Crawlers"
屏幕截图:
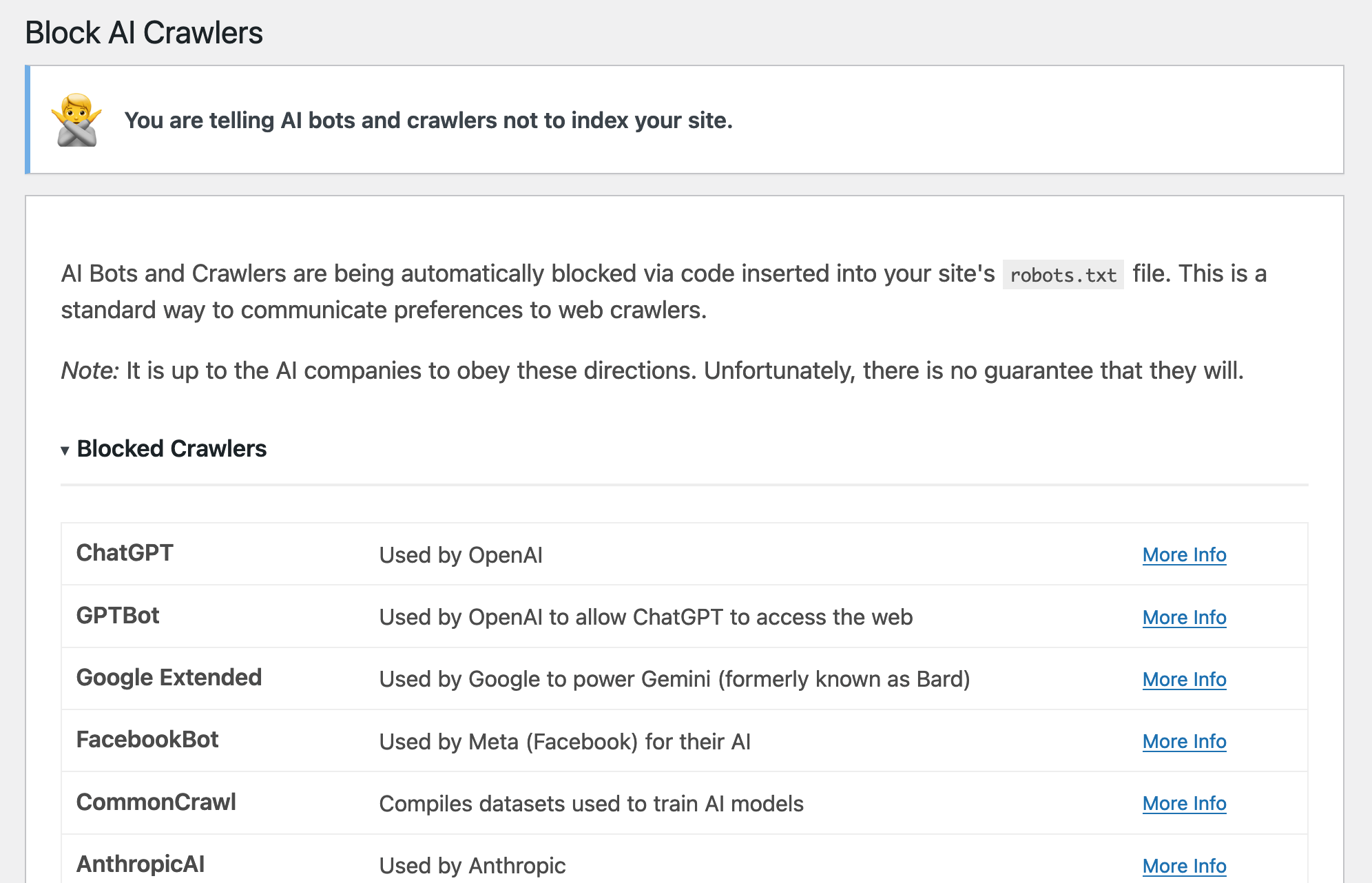
常见问题:
Will this remove my site from existing data sets?
Unfortunately, no. However, it does tell bots that your site shouldn't be used for future datasets.
How does this work?
The plugin adds directives to the robots.txt file to tell AI crawlers that they shouldn't index your site. It also adds the noai meta tag to your site's header to do the same.
How often is this updated?
I try to keep up with new crawlers and update the block list regularly.
Can I suggest crawlers for blocking?
Yes! please share suggestions on the forums or on GitHub.
What if I already have a robots.txt file on my web server?
If you have a physical robots.txt file on your web server, you won't be able to activate this plugin. The plugin only works when using WordPress' built-in virtual robots.txt.
Will this work with other plugins that modify the virtual robots.txt?
It should in theory. It just appends the directives to the robots.txt file.
Will this prevent my site from being indexed by search engines?
No. Search engines follow different robots.txt rules.
更新日志:
1.5.6 - 02/15/2026
- Fix: Update Claude blocking
- New: Block MistralAI-user
- New: Block LinerBot
- New: Block Google-CloudVertexBot
- New: Block VelenPublicWebCrawler
- Indicate WordPress v6.9 compatibility
- Fix: Variable naming issues identified by Plugin Check
- Bump version number
- New: Block Brightbot
- New: Block DeepSeekBot
- New: Block TerraCotta
- Fix: Plugin check errors
- New: Block Yak
- New: Block Bigsur.ai
- New: Block AddSearchBot
- New: Block Google Agents
- New: Block Thinkbot
- New: Block Posideon Research Center
- New: Block EchoboxBot
- New: Block Bedrockbot
- New: Block Panscient
- New: Block SBIntuitionsBot
- New: Block PhindBot
- New: Block YandexAdditional
- New: Block aiHitBot
- New: Block Cotoyogi
- New: Block Factset
- New: Block Firecrawl
- New: Block TikTokSpider
- New: Block Perplexity‑User
- Update: Meta External Agent and Meta External Fetcher
- Update: New Claude Bots
- Update: Indicate WordPress v6.8 compatibility
- Enhancement: Adds ability for custom robots.txt rules
- New: Block SemrushBot
- New: Block Crawlspace
- New: Block PanguBot
- New: Block Turnitinbot
- New: Block Ai2Bot-Dolma
- Enhancement: WordPress 6.7 compatibility
- New: Block Kangaroo Bot
- New: Block sentibot
- New: Block FriendlyCrawler
- New: Block Scrapy
- Fix: Broken link to settings page from Plugins page
- Enhancement: Improve
readme.mdandreadme.txt
- New: Block PetalBot
- New: Block AI2Bot
- New: Block Webz.io
- New: Block OpenAI Search Bot (SearchGPT)
- Enhancement: Alphabetize list of blocked crawlers
- Enhancement: Indicate compatibility with WordPress v6.6
- Enhancement: Add quick link to settings and nudge for rating on plugins page
- Maintenance: Auto-deply from Github fixed / bumped version number
- New: Meta AI
- New: Block You.com Crawler
- New: Block AmazonBot
- New: Block Timpibot
- New: Block Perplexity
- New: Block Apple AI
- Update: FAQ based on submitted question
- New: Block additional Omgili bot
- New: Block Imagesift
- Fix: Fix settings page
- Add:
blueprint.jsonfor plugin preview
- Fix: Issue with fatal errors on activation
- New: Blocks Anthropic's Claude
- Fix: Missing external link icons
- Update: Bump tested to v6.5.3
- New: Adds settings page showing blocked crawlers
- Enhancement: Remove crawler description in
robots.txt
- Update: Adds deploy from GitHub
- Maintenance: Adds deploy from GitHub
- Block Cohere crawler
- Block DiffBot crawler
- Block Anthropic AI crawler
- Indicate compatibility w/WordPress 6.5.2
- Blocks additional crawlers.