
LLMs.txt Curator
| 开发者 | seanmullins |
|---|---|
| 更新时间 | 2026年7月8日 01:16 |
| PHP版本: | 7.4 及以上 |
| WordPress版本: | 7.0 |
| 版权: | GPLv2 or later |
| 版权网址: | 版权信息 |
详情介绍:
llms.txt file for AI assistants and retrieval systems, ensuring only relevant, well-described content is exposed to large language models.
It generates and maintains llms.txt and llms-full.txt — the emerging standard for telling AI systems (ChatGPT, Claude, Perplexity, Gemini, and others) which pages on your site matter most and what they contain.
Unlike auto-generators that dump every URL into a flat file, LLMs.txt Curator takes a curation-first approach. You choose the pages, organise them into sections, fill descriptions, override titles for AI, validate quality, and see exactly which AI bots are reading your file — all from a single interface.
What llms.txt is, and what it isn't (June 2026)
Being straight with you matters more than overselling. Google Search ignores llms.txt: it will not help or harm your Google rankings, and Google confirmed in June 2026 that it is fine to maintain the file for other systems that do read it. So this plugin is not an "AI ranking" tool.
Where the file genuinely earns its place: on-site navigation for agents already on your site, the surfaces that actually read it (such as Perplexity and coding agents), and passing Chrome's Agentic Browsing audit. The honest, useful question is not "does this rank me" but "which AI bots are actually reading my file", and this plugin is the only one that answers it from your own server logs.
What makes this different
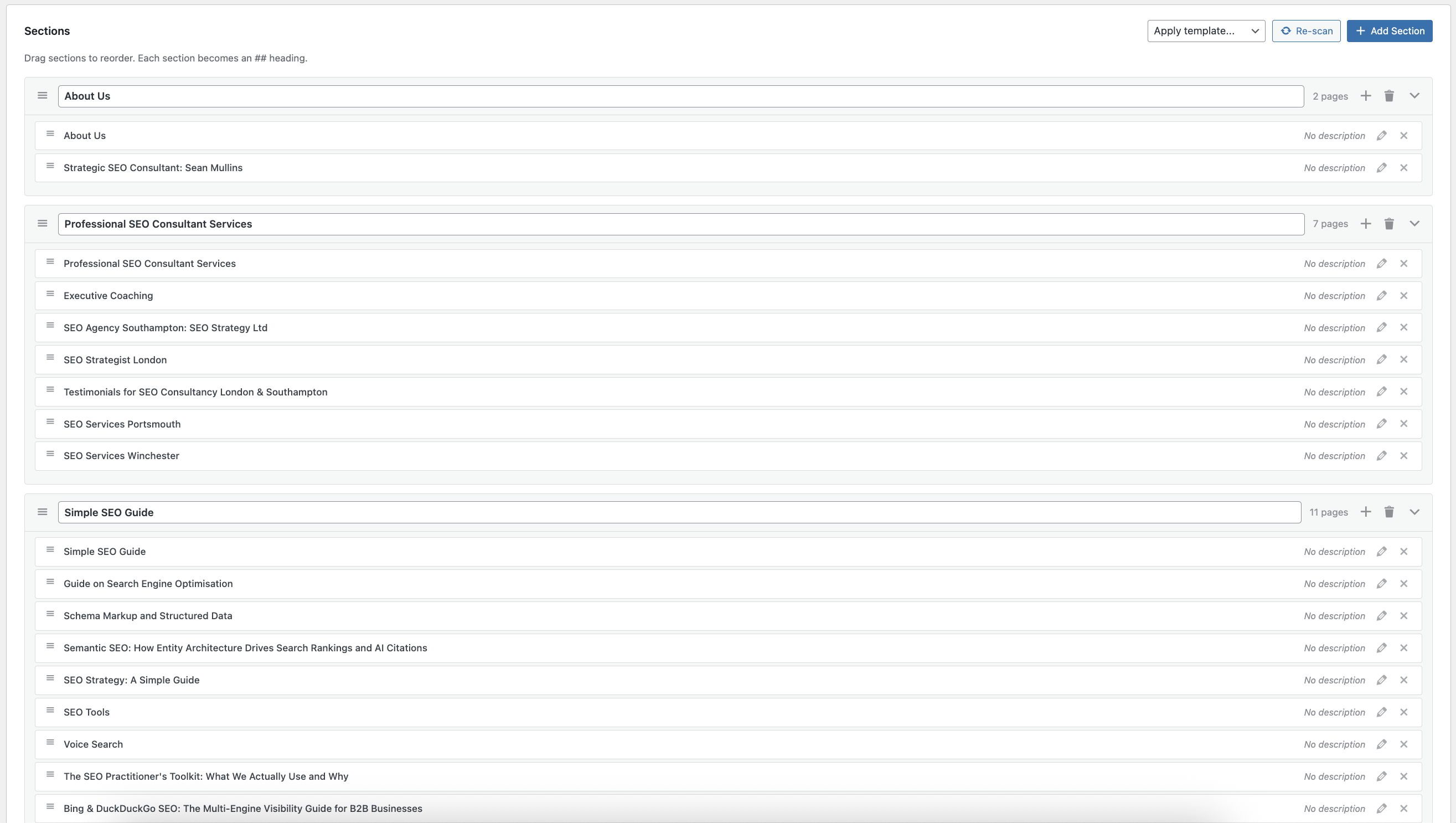
Most llms.txt plugins treat the file as a static output. LLMs.txt Curator treats it as a living asset:
- Quality Score — every generated file shows your coverage percentage, which pages have descriptions, and which still need attention.
- Description Suggestions — one click fills all missing descriptions from a five-step fallback chain (SEO meta → excerpt → Open Graph → page content). Never overwrites what you've set manually.
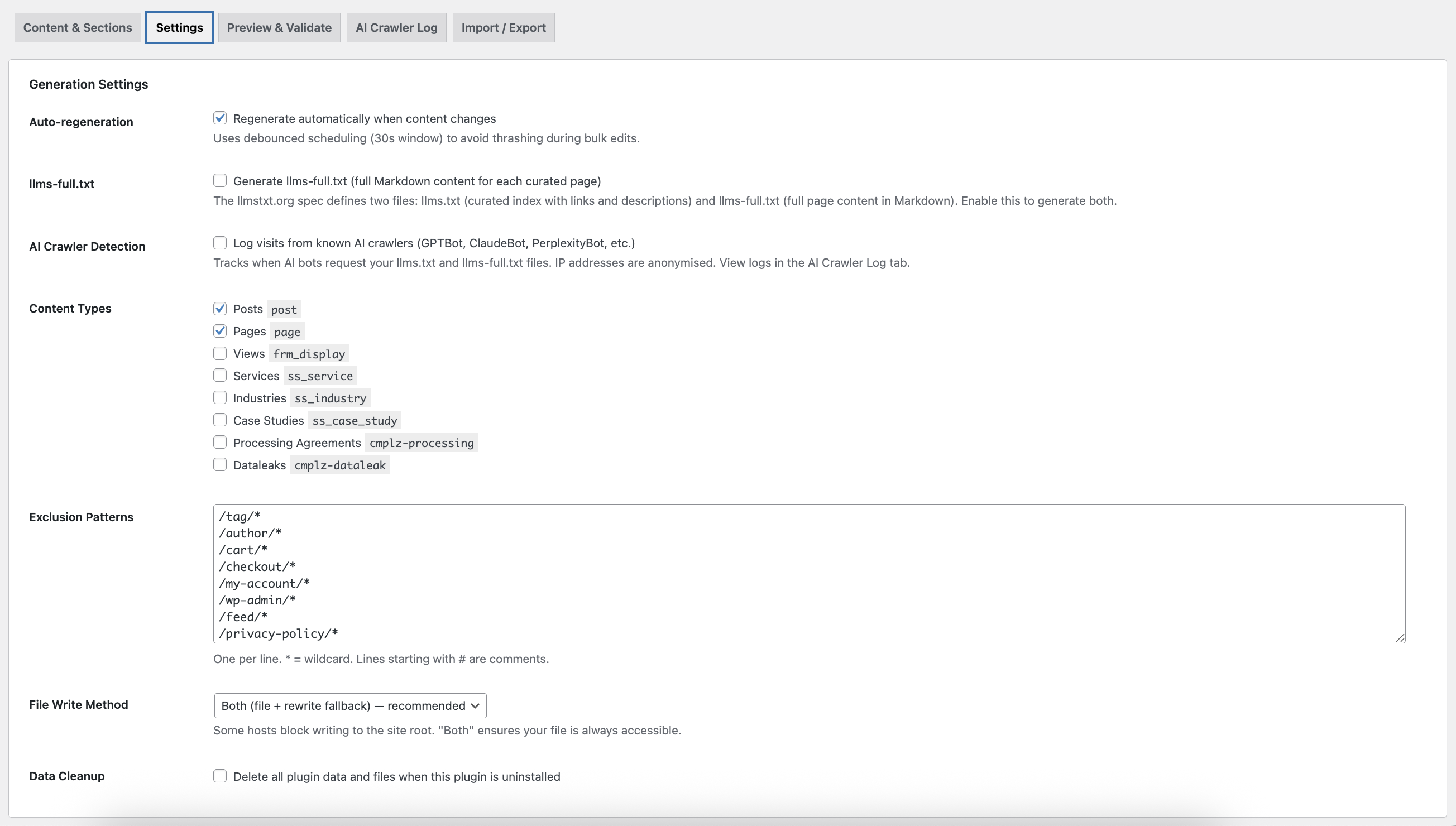
- Change Detection — a banner appears in your admin when curated pages have been updated since the last generation, with a Regenerate Now button. Your llms.txt stays current without manual checking.
- Per-Page Title Override — set a different title for each page specifically for AI consumption, without touching your on-site SEO.
- Safety Mode — blocks generation if validation errors exist, preventing a broken file from going live. Includes an on-demand validator with plain-English results.
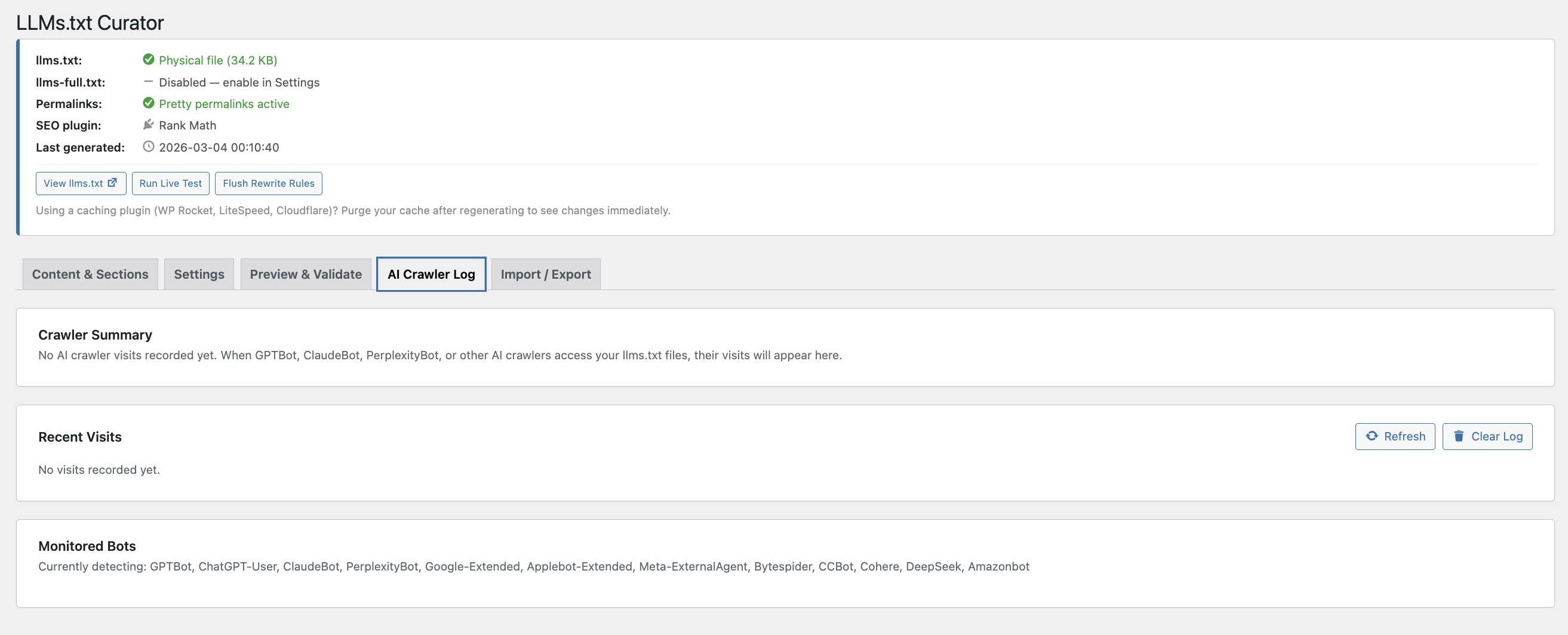
- AI Crawler Analytics — see which bots visited in the last 7 days, with a visual bar chart. OpenAI, Anthropic, Perplexity, Google — know who is actually reading your file.
- Drag-and-drop curation — reorder sections and pages visually; each section becomes an
##heading per the spec - llms-full.txt generation — the companion file with full Markdown content for each curated page
- Five SEO plugin integrations — Rank Math, Yoast SEO, All in One SEO, SEOPress, The SEO Framework
- Schema-aware descriptions — uses structured data before falling back through the description chain
- Scheduled regeneration — choose Instant (on publish), Daily, Weekly, or Manual
- WooCommerce support — SKU, price, stock, categories, dimensions; respects product visibility
- WordPress Multisite — network-activate across all sites; each site manages its own independent llms.txt; Network Admin overview with per-site and bulk regenerate
- Pre-built templates — Business, E-commerce, SaaS, Blog, Local Business
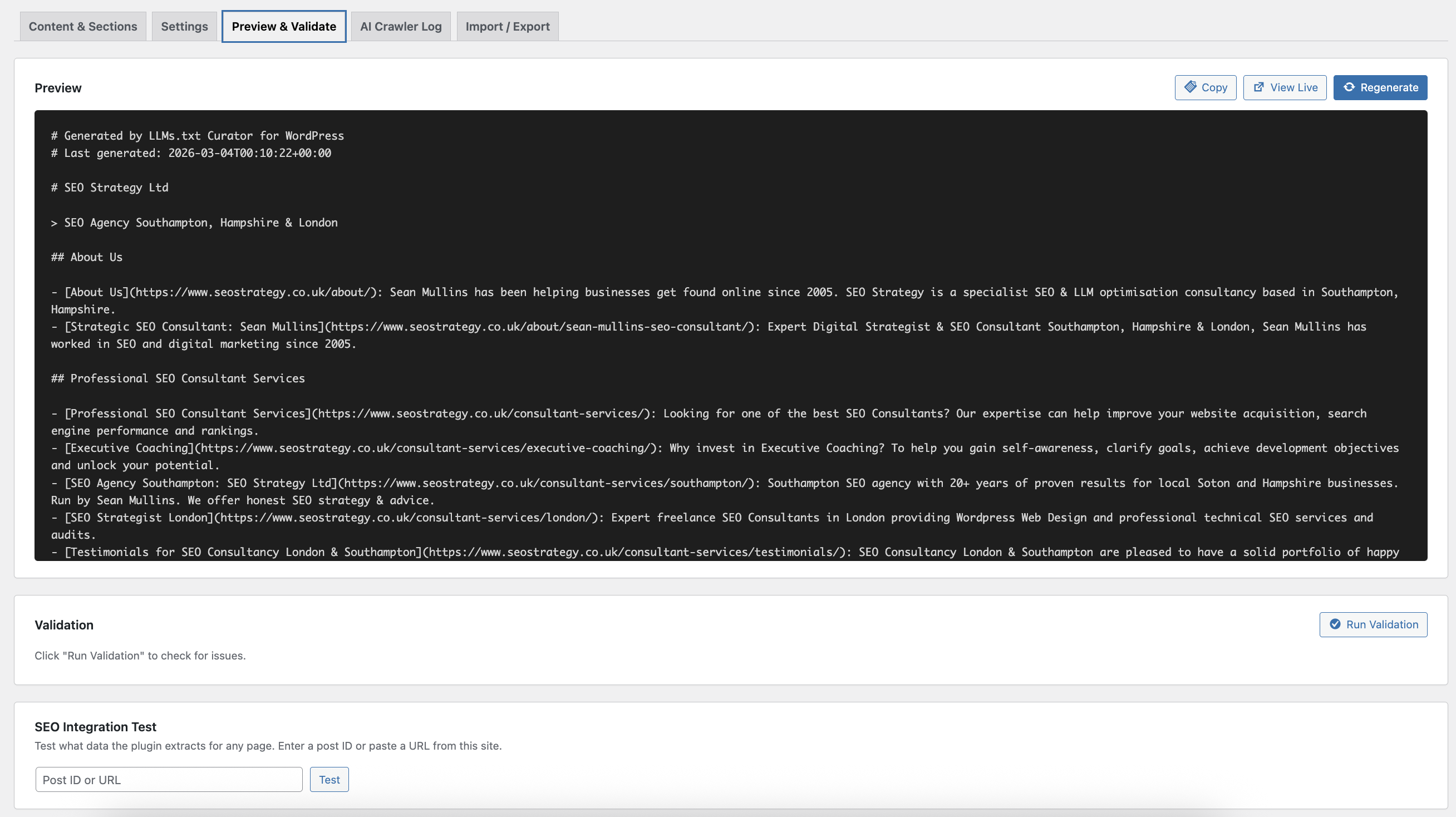
- Live preview — see your exact llms.txt output before saving
- Import / export — move your configuration between sites as JSON
- WP-CLI —
wp llms-txt regenerate,wp llms-txt status,wp llms-txt crawler-log - REST API —
POST /wp-json/llms-txt/v1/regenerate,GET /wp-json/llms-txt/v1/status - Atomic file writes — temp file → rename; no half-written files served to bots
- ETag/304 caching — proper HTTP headers for CDN revalidation
- Subdirectory / Bedrock support — correctly finds the site root on non-standard installs
- Robots.txt reference — automatically adds a spec-compliant comment
- Schema markup (Rank Math, custom
_schema_json) - SEO plugin meta description
- WordPress excerpt
- Open Graph description (
_og_description/og_description) - First 160 characters of post content
llms.txt ends with a coverage report:
Quality Score: 94%
Pages included: 48
Pages with descriptions: 45
Pages missing descriptions: 3
This is visible to the AI systems reading your file, and to you in the Preview tab.
AI Crawler Analytics
Track 12 known bots: GPTBot, ChatGPT-User, ClaudeBot, PerplexityBot, Google-Extended, Applebot-Extended, Meta-ExternalAgent, Bytespider, CCBot, Cohere, DeepSeek, Amazonbot.
The 7-day analytics card shows a visual bar chart of recent activity. All-time totals are kept separately. IP addresses are anonymised before storage — last octet zeroed for IPv4, last 80 bits for IPv6. No data leaves your server.
Safety Mode
Before generation, the validator checks:
- Pages missing or unpublished
- Duplicate URLs across sections
- Noindex conflicts
- Canonical mismatches
- Password-protected pages
- Thin content (< 100 words, no meta, no excerpt)
- File size > 50 KB
- Too many pages (> 80)
- Instant — regenerates ~30 seconds after any page is published or trashed (default)
- Daily — once per day, via WP-Cron recurring event
- Weekly — once per week
- Manual — only when you click Save & Generate
- Install and activate. The plugin auto-scans your content and creates initial sections.
- Curate: drag, drop, add, remove. Aim for 20-60 pages that best represent your site.
- Click Generate Missing Descriptions to fill gaps automatically.
- Fix any warnings shown in the Safety Mode card.
- Set the update mode that suits your workflow.
- Save & Generate. Your files are live at
/llms.txtand/llms-full.txt. - Enable the AI Crawler Log to see which bots start visiting.
llms.txt descriptions, and full product details in llms-full.txt. Products with "hidden" visibility are excluded, and you can optionally exclude out-of-stock products.
Developer hooks
llmscu_capabilityfilter — override the required capability (default:manage_options)llmscu_post_limitfilter — scanner post limit per type (default: 500)llmscu_full_word_limitfilter — per-page word cap inllms-full.txt(default: unlimited)llmscu_regeneratedaction — fires after each successful regeneration with the content string
安装:
- Upload the
llms-txt-curatorfolder to/wp-content/plugins/. - Activate through the 'Plugins' menu.
- Go to Settings -> LLMs.txt Curator to begin curating.
屏幕截图:
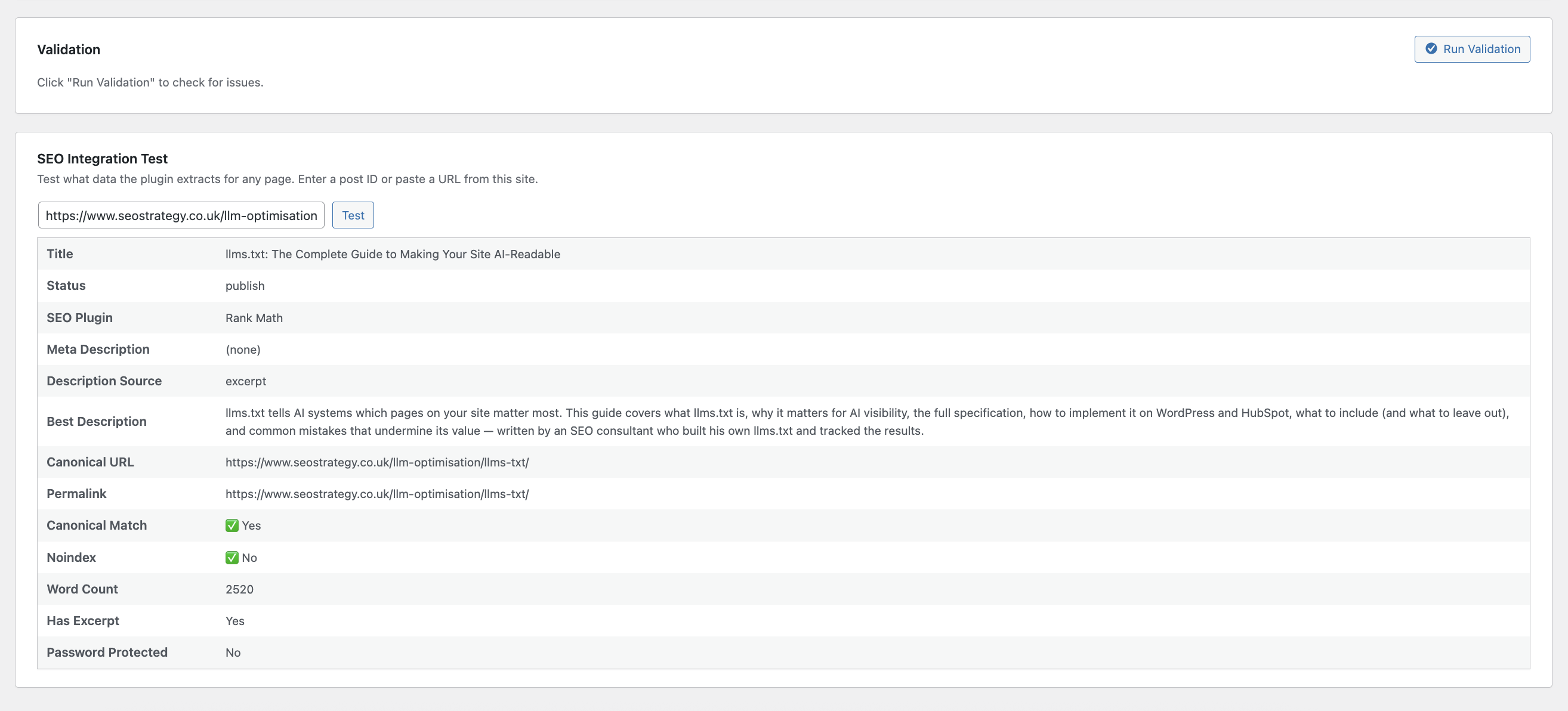
常见问题:
What is llms.txt?
llms.txt is a proposed standard (llmstxt.org) that provides AI systems with a curated, Markdown-formatted overview of a website's most important content. A strategic selection of the pages you want AI to know about -- not a sitemap.
What is llms-full.txt?
The companion file defined in the same spec. While llms.txt contains links and short descriptions, llms-full.txt contains the full Markdown content of each page. Optional -- enable it in Settings when ready.
Do I need both files?
No. llms.txt alone is sufficient. llms-full.txt is useful if you want AI systems to have immediate access to your full content without additional crawling.
What does Description Suggestions do?
Scans every curated page and fills missing descriptions using a five-step fallback chain: schema markup -> SEO meta -> excerpt -> Open Graph -> page content. Pages with descriptions already set are never touched.
What is the Quality Score?
A percentage showing how many listed pages have descriptions. It appears at the bottom of your generated llms.txt, visible to both you and any AI systems reading the file.
What does Title Override do?
Lets you set a different title for a page in your llms.txt output without changing it on your site. Useful when your WordPress title includes your site name but you want AI to see a cleaner, more descriptive title.
What does Safety Mode do?
Runs validation before every generation. If errors are found, generation is blocked and results shown immediately. Prevents broken or malformed files going live.
Which SEO plugins are supported?
Rank Math, Yoast SEO, All in One SEO, SEOPress, and The SEO Framework.
Which AI bots does the crawler log detect?
GPTBot (OpenAI), ChatGPT-User, ClaudeBot (Anthropic), PerplexityBot, Google-Extended, Applebot-Extended, Meta-ExternalAgent, Bytespider (ByteDance), CCBot (Common Crawl), Cohere, DeepSeek, and Amazonbot.
What if my host blocks file writes?
The plugin has a rewrite rule fallback that serves both files via WordPress. Choose between "Direct file", "Rewrite rule only", or "Both" (recommended) in Settings.
Does this work on multisite?
Yes. Activate network-wide from Network Admin > Plugins, or activate per-site on individual sub-sites.
Each site manages its own independent llms.txt — there is no shared network file. The Network Admin overview page (Network Admin > Settings > LLMs.txt Curator) shows every site's generation status and lets you regenerate any site, or all sites at once, without leaving the network admin.
On subdirectory networks (example.com, example.com/site1) each site writes a physical file at its own path. On subdomain networks (example.com, site1.example.com) sub-sites share a filesystem root, so they serve llms.txt via WordPress rewrite rule from the database instead — this is fully correct and functionally identical.
WP-CLI works per-site using the standard --url= flag: wp llms-txt regenerate --url=https://site1.example.com
Is any data sent externally?
No. Everything stays on your server. No telemetry, no external API calls, no cookies. Crawler IP addresses are anonymised before storage.
更新日志:
- Fix: generated llms.txt and llms-full.txt now contain exactly one H1 (the site name), per the llms.txt spec. The attribution and "last generated" lines are now HTML comments instead of Markdown H1 headings, and the Coverage Report footer is now an H2. This clears the "more than one H1 title" warning reported by third-party llms.txt validators.
- Compat: files written by earlier versions are still recognised as plugin-owned after upgrade — ownership detection now matches the invariant signature text in both the new comment form and the legacy heading form. The corrected file is written on the next regeneration (save settings, click Regenerate, or wait for the scheduled run).
- New: Content Signals (contentsignals.org) — declare ai-train / search / ai-input preferences in your robots.txt, separating "you may read me" from "you may train on me". Opt-in, so an existing install never has a stance set silently; when enabled, all three default to yes.
- New: Link: rel="describedby" response header — points agents at your llms.txt before they parse HTML (RFC 8288 registered rel). Default on, front-end only, respects subdirectory installs.
- Update: repositioned around Google's June 2026 guidance — clarified that Google Search ignores llms.txt (no ranking help or harm) and that the file's value is on-site agent navigation, the surfaces that read it (Perplexity, coding agents), and Chrome's Agentic Browsing audit.
- Update: AI Crawler Analytics surfaced as the primary value — the one thing no other llms.txt plugin does.
- Compat: Tested up to WordPress 7.0. Minimum PHP remains 7.4.
- Fix:
sanitize_all_settings()now validates thatsections,post_types,descriptions, andtitle_overridesare arrays before passing them to helper functions orarray_map(). Previously used?? array()fallbacks which guard against null but not wrong types from malformed JSON, risking aTypeErroron PHP 8+. - Fix:
sanitize_sections()now validatespagesis an array before iterating it. - Fix:
sanitize_descriptions()andsanitize_title_overrides()now skip non-string values. - Fix:
post_typesoutput wrapped inarray_values( array_filter() )to strip any empty keys produced bysanitize_key().
- Fix:
ajax_preview()now passes POST data throughsanitize_all_settings()before use, consistent withajax_save_settings(). Previously usedwp_parse_args()without sanitization.
- New: 30-day AI crawler activity chart — stacked bar chart showing daily visits per bot, auto-compressed to weekly buckets for readability.
- New: "Last AI crawler visit" banner at the top of the Crawler tab — shows a live "X minutes/hours/days ago" timestamp at a glance.
- New: First Seen / Last Seen columns in the all-time bot summary table.
- New: Export CSV button — downloads the full crawler log as a CSV file for use in client reports.
- New: Daily aggregate storage (90-day rolling window) — daily visit counts are now stored separately from the raw log, enabling the timeline chart without scanning every log entry.
- New: REST API endpoint
GET /wp-json/llms-txt/v1/crawler-stats— returns all-time, 7-day, 30-day, daily, and per-bot first/last seen data. - New: REST API endpoint
GET /wp-json/llms-txt/v1/pages— returns all curated sections and pages as JSON, useful for external dashboards. - Improvement: All-time bot table now includes Last 7 Days column alongside All-Time for quick comparison.
- Fix: All PHP declarations, stored data keys, and WordPress registrations updated to use the distinct
llmscu_/LLMSCU_prefix throughout, replacing the genericllms_txt_/LLMS_Txt_prefix. No data migration required — existing stored options are unaffected. - Fix: Readme comparative claims removed per WordPress plugin guidelines.
- Fix: Reverted v1.3.2 RewriteRule approach which caused llms.txt 404 on some hosts. Replaced with a safe + mod_headers .htaccess block that sets Content-Type charset and X-Robots-Tag without touching WordPress rewrite rules.
- Fix: UTF-8 encoding bug causing em dashes and other multibyte characters to render as â€" in browsers and AI crawlers. Physical llms.txt file is now always routed through WordPress via .htaccess rules so the correct Content-Type: text/plain; charset=utf-8 header is always sent.
- New: X-Robots-Tag: noindex header option — prevents Google indexing llms.txt as a page in search results. Enabled by default; toggle in Settings tab under Search Indexing.
- Security:
X-Content-Type-Options: nosniffheader added when serving llms.txt and llms-full.txt. - Security: Import JSON payload capped at 256 KB — rejected before decode with a plain-English error.
- Security: Import schema sanity check — requires at least 2 expected top-level keys before accepting a configuration file.
- Robustness: 2 MB file size guard before
file_get_contents()— falls through to DB option if the physical file exceeds the cap. - Performance:
no_found_rows,update_post_meta_cache => false,update_post_term_cache => falseadded to allget_posts()queries. - New: Site Diagnostics panel on the Preview & Validate tab — shows computed root, writable status, delivery mode, file/DB state, rewrite health, last live test result, and environment versions.
- New: "Last verified" status bar row — persisted after every live test so it survives page reloads.
- New: Reachability health banner — shown above tabs when the last live test failed; includes one-click "Fix: Flush Rewrite Rules" button that reruns the test automatically.
- Fix: Multisite uninstall loop changed from a fixed 500-site cap to a paginated do/while loop (100 per page) — handles networks of any size.
- Fix:
@packagedocblock corrected fromLLMS_Txt_ManagertoLLMS_Txt_Curatoracross all PHP files. - Fix:
load_plugin_textdomain()added — plugin is now translation-ready.
- New: Multisite support (Chunks A–E — complete). Plugin header
Network: true, network activation, per-site isolation, file path safety, network admin overview, and cron verification all done. - New: Network Admin overview page (Network Admin > Settings > LLMs.txt Curator) with summary strip, per-site status table, per-site Regenerate button, and Regenerate All Sites bulk action. Table updates live via AJAX without a page reload.
- New: File mode column in network table — "Physical" (subdirectory) or "Rewrite" (subdomain/domain-mapped) with tooltip.
- New: Regen schedule shown per-site in the network table.
- New: Network Settings action link in the Network Admin plugins list.
- New:
llms_txt_is_network_activated()helper function. - New:
llms_txt_file_write_safe()helper — prevents subdomain sub-sites from overwriting the main site's physical llms.txt. Those sites serve via rewrite rule instead. - New:
next_regenkey inget_file_status()— formatted next scheduled regeneration time (daily/weekly/instant debounce) for the current site. - Improvement:
maybe_schedule_recurring_regen()now returns early onis_network_admin()— prevents the main site's cron schedule being unnecessarily re-synced on every network admin page load. - Improvement: All four cron methods updated with explicit multisite docblocks confirming per-site safety.
- Improvement: WP-CLI handler docblock updated with
--url=guidance for per-site usage on multisite networks. - Improvement:
delete_file()in the generator guarded against subdomain sub-sites deleting a shared file. - Improvement: Activation hook accepts
$network_wide; deactivation clears cron events across all sites. - Improvement: Uninstall iterates all sites; cleans up options, transients, cron, and files per-site.
- Improvement:
LLMS_Txt_Adminguarded from instantiating in network admin context. - Improvement:
get_file_status()returnsis_network_activated,is_subdomain_network,file_write_safe,network_overview_url, andnext_regen. - Improvement: Validator surfaces info message on subdomain sub-sites confirming rewrite serving is intentional.
- Improvement: Admin status panel and multisite notice contextually correct per site type.
- Confirmed (docblocked): WP-Cron, option storage, transients, nonces, and capability checks are all natively per-site in multisite. No
switch_to_blog()wrapping required in any cron path. - Removed:
wp_die()block that previously blocked activation on non-main sites.
- New: AI Crawler Analytics -- 7-day bot activity bar chart on the Crawler Log tab, showing visit counts per bot. Refreshes without a page reload.
- Improvement: Crawler Log tab restructured -- analytics card at top, all-time summary below, full visit log at the bottom.
- Update: readme.txt updated to reflect all features added in v1.2.x.
- Update: Stable tag updated to 1.2.2.
- New: Scheduled Regeneration -- choose between Instant, Daily, Weekly, or Manual update modes. Daily/Weekly use proper WP-Cron recurring events with next-run time displayed in the UI.
- New: Safety Mode -- toggle to block generation on validation errors, with an on-demand validation card showing errors, warnings, and a plain-English stats summary.
- New: Description Suggestions -- one-click fills missing descriptions using a five-step fallback chain. Never overwrites manually-set descriptions.
- New: Quality Score footer -- every generated file includes a Coverage Report showing quality score %, pages with descriptions, and pages needing attention.
- New: Change Detection -- admin banner alerts when curated pages have been updated since last generation, with direct Regenerate Now action.
- New: Per-page Title Override -- set an AI-optimised title for any page without touching on-site SEO.
- Improvement: OpenGraph description added as step 4 in the description fallback chain.
- New: llms-full.txt generation -- full Markdown content for each curated page, per the llmstxt.org spec.
- New: AI crawler detection -- logs visits from 12 known AI bots with anonymised IPs.
- New: WooCommerce integration -- product data (SKU, price, stock, categories, dimensions) automatically included.
- New: AI Crawler Log tab with summary stats and detailed visit log.
- New: WP-CLI commands:
status,crawler-log,crawler-clear. - New: REST API status endpoint.
- New: robots.txt reference and rewrite rule for llms-full.txt.
- Initial public release. Drag-and-drop curation, validation engine, SEO plugin integration, schema-aware descriptions, pre-built templates, auto-regeneration, live preview, import/export, WP-CLI, REST API, atomic file writes, ETag caching.