
WebEquipe PDF Search
| 开发者 |
webequipe
codersbucket bdsarwar |
|---|---|
| 更新时间 | 2026年6月21日 18:45 |
| PHP版本: | 7.4 及以上 |
| WordPress版本: | 7.0 |
| 版权: | GPLv2 or later |
| 版权网址: | 版权信息 |
详情介绍:
- Standard Text PDFs: Works flawlessly out of the box with digital PDFs exported from Word, Google Docs, InDesign, etc. File size default 50MB, configurable up to 500MB in PDF Search → Settings.
- Mixed Layout PDFs: If some pages contain extractable text and others are image-only, indexing succeeds with an admin warning; core search covers the native text pages.
- Scanned or Image PDFs: Image-only or scanned PDFs with no embedded text are marked Error in the free version. To make these searchable, WebEquipe PDF Search Pro uses automated OCR to extract and index the text for you.
- Protected Files: Password-protected PDFs cannot be indexed.
- Install and activate the plugin.
- Open PDF Search in the WordPress admin sidebar (Dashboard is the home screen).
- Click Re-index All PDFs on the Dashboard or PDF Search → Index Activity to index existing PDFs (new uploads are indexed automatically when Enable PDF Indexing is on).
- Use your site's search or add the shortcode
[webequipe_pdf_search_form]on a page—PDFs will appear in results when Enable Search Integration is enabled.
- General – Enable PDF indexing on upload, include PDFs in WordPress search, maximum file size (50MB default), search result excerpt length.
- Indexing options – Batch size (PDFs per re-index step), pages per batch (background page steps), page index threshold (when large PDFs switch to page-by-page indexing), max page content length (0 = unlimited; re-index after changing).
- Search display options – Show or hide PDF icon, file size, page count, last updated date, author, thumbnail preview, and summary/snippet text in search results.
- Advanced – Debug logging, memory limit, processing timeout, background processing, delete data on uninstall.
- Dashboard – Indexed PDF count, pages indexed, coverage, search health, recent activity, quick links, and Re-index All PDFs (status banner uses live index data).
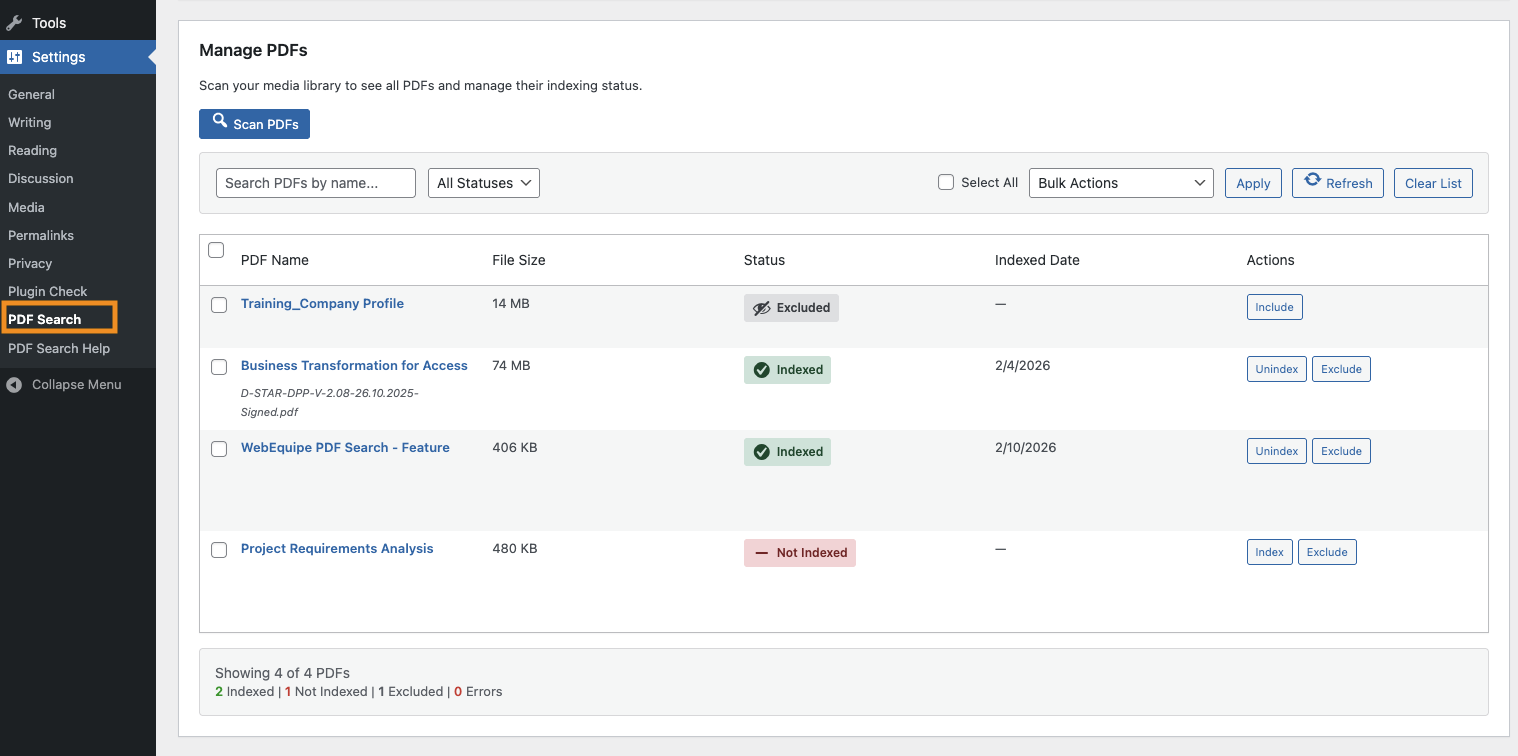
- Manage PDFs – Scan the library, filter by status (including Processing / Scheduled), cancel in-flight jobs, bulk actions, and accurate Re-index All progress with a do-not-refresh notice.
- Full-text search – Search inside PDF content by page; one result per PDF with the best-matching excerpt.
- Control each PDF – Index, unindex, exclude, or retry from the Media Library, Manage PDFs, or the attachment screen.
- Bulk actions – Index, unindex, include, or exclude multiple PDFs at once (Media Library or Manage PDFs).
- Index Activity – Filterable log of every indexing run, stats, and CSV export.
- Search display – Configure icons, meta, previews, and excerpts in settings.
- Shortcode – Add a PDF-only search form with
[webequipe_pdf_search_form](see PDF Search → Help). - Background processing – Large PDFs above the page threshold are indexed page-by-page in the background to avoid timeouts.
- Multilingual interface – Admin and front-end text is translated into French, German, Dutch, and Swedish, loaded automatically based on your WordPress language setting.
- Free Plan: Full-text search for standard PDFs, auto-indexing, and shortcode integration. (Forever Free)
- Starter Plan: Adds Cloud OCR (up to 1,000 pages/month) and advanced search filtering.
- Pro Plan: Adds Private PDF Search, the full Search Analytics Dashboard, and higher OCR limits (3,000 pages/month).
- Agency Plan: Includes everything, White-Label mode, volume OCR processing (10,000 pages/month), and unlimited site licenses.
安装:
- Go to Plugins → Add New.
- Search for "WebEquipe PDF Search", install, and activate.
- Download the plugin zip.
- Go to Plugins → Add New → Upload Plugin, upload the zip, then install and activate.
- Open PDF Search → Settings and review the options your site needs:
- Enable PDF Indexing – on if new uploads should index automatically (recommended).
- Enable Search Integration – on if PDFs should appear in your theme's normal site search.
- Maximum File Size – raise only if you index PDFs larger than the default 50MB.
- Indexing options – adjust batch size or page-batch settings if you have very large PDFs or timeouts (defaults work for most sites).
- Search display options – choose what visitors see in PDF search results (icon, size, pages, author, preview, excerpt). Click Save Changes when finished.
- Go to PDF Search → Dashboard and click Re-index All PDFs to index PDFs already in your Media Library.
- Wait for indexing to finish (large libraries run in batches; check PDF Search → Index Activity for progress and any errors).
- Test your site search or a page with
[webequipe_pdf_search_form]to confirm PDFs appear. - Optional: use PDF Search → Manage PDFs to scan the library, exclude private files, or index individual PDFs; use Media → Library for the same actions on each file.
- If you upgraded from 1.1.x or earlier, step 2 is required once so the per-page index replaces legacy data (an admin notice appears until you re-index).
- See PDF Search → Help for full documentation and troubleshooting.
屏幕截图:
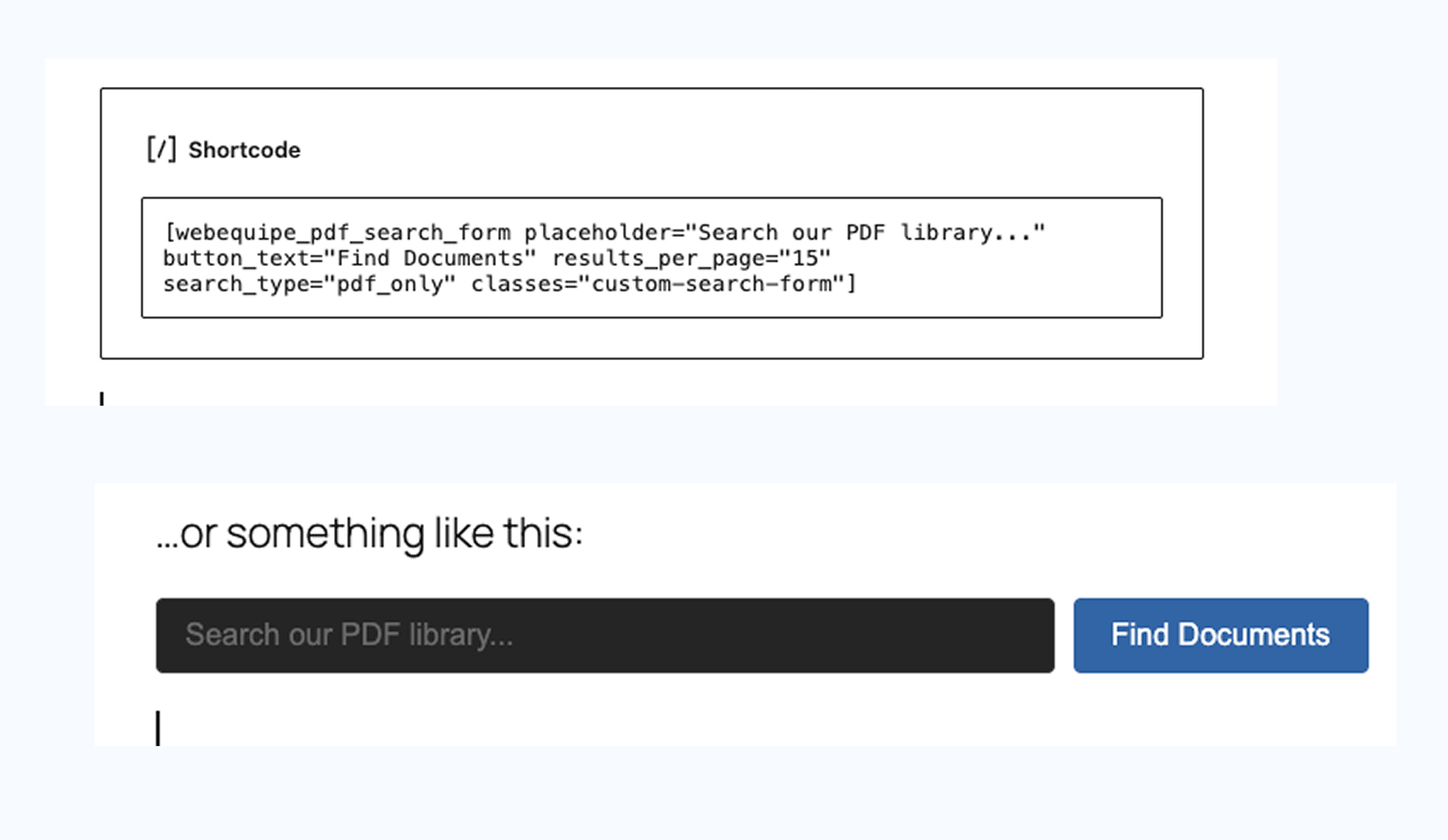
![Shortcode – copy the [webequipe_pdf_search_form] shortcode with custom attributes and embed a PDF-only search form anywhere on your site.](https://cdn.jsdelivr.net/wp/webequipe-pdf-search/assets/screenshot-8.png)
常见问题:
What kind of PDFs are supported?
Standard, text-based PDFs (e.g., exported from Word or Google Docs) are fully supported. Default max size is 50MB (up to 500MB in settings). Scanned or image-only PDFs with no extractable text are marked Error in the free plugin. To index these, use WebEquipe PDF Search Pro for built-in Optical Character Recognition (OCR), or run OCR software externally before uploading. Password-protected PDFs cannot be indexed. Mixed PDFs (some text pages, some image-only) index with a warning; search uses the text pages only.
Does it work with scanned PDFs using Optical Character Recognition (OCR)?
Not in the free version. Scanned PDFs are read by search engines as flat images with no extractable text—the free plugin flags them as an Error. WebEquipe PDF Search Pro (Starter plan and above) integrates advanced Cloud Optical Character Recognition (OCR) to scan text from images automatically on upload. No pre-processing or external software needed. See Pro plans →
Can I restrict certain PDFs to logged-in users only?
Not in the free version. The free plugin's Exclude feature keeps PDFs out of search entirely, but cannot show them dynamically based on user status. Private PDF Search is available on Pro and Agency plans—mark any PDF as Private and it becomes invisible in search for logged-out visitors while remaining fully searchable for logged-in members. See Pro plans →
Is there an analytics dashboard to see what visitors search for?
Not in the free version. The Analytics Dashboard—showing top search queries, zero-result searches, and most-clicked PDFs—is available on Pro and Agency plans. Zero-result queries show you exactly what content visitors need but can't find. See Pro plans →
Is there a Pro version available?
Yes. WebEquipe PDF Search Pro adds native Optical Character Recognition (OCR) for scanned PDFs, Private PDF search filters for logged-in users, an integrated Analytics dashboard, advanced search weights, white-label mode (Agency), and more. View plans and pricing →
Why don't my PDFs appear in search?
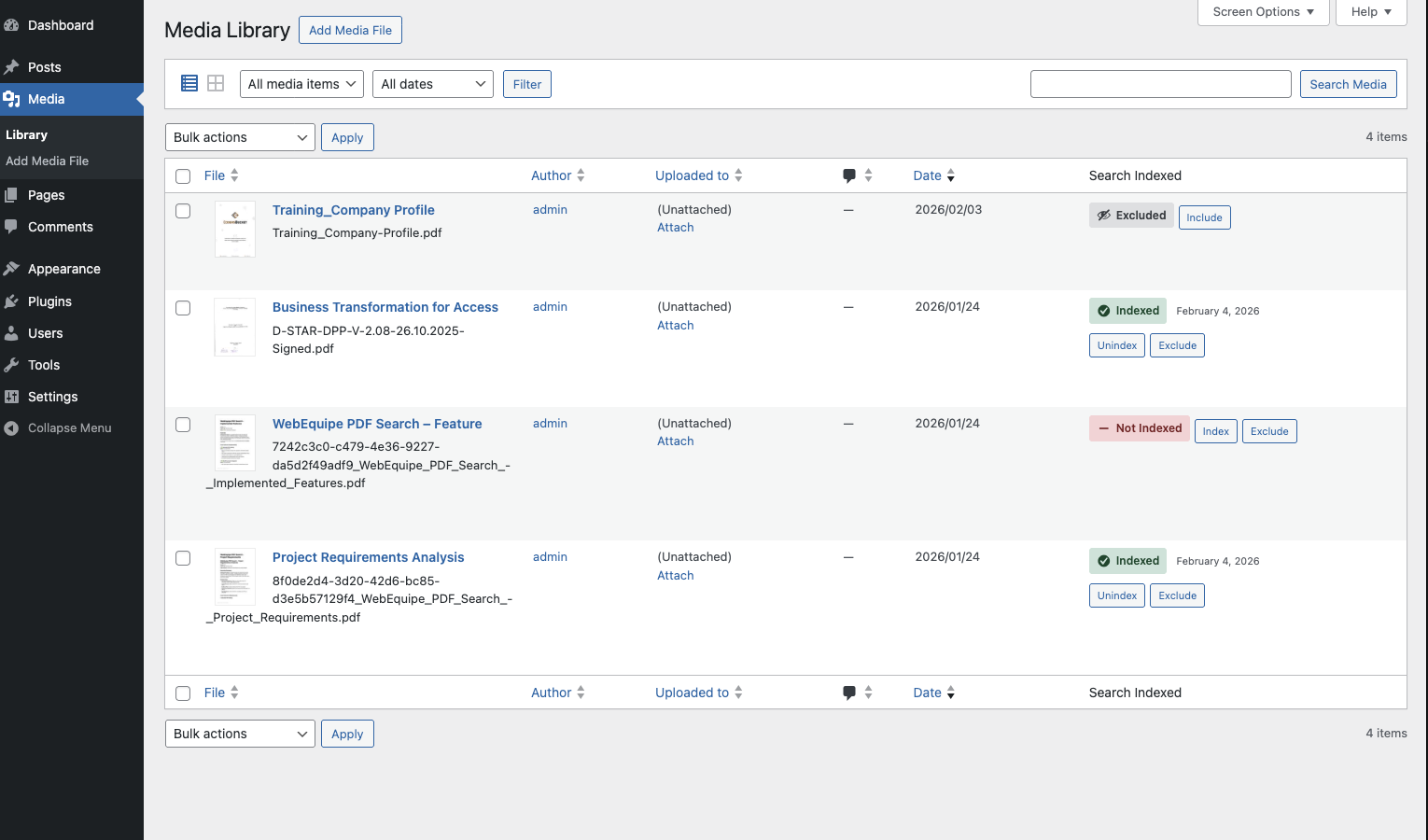
- Ensure they are indexed: in Media → Library, check the "Search Indexed" column (green check = indexed; Error or Not Indexed need action).
- If not indexed, use Index on the PDF, bulk Index PDFs, or Re-index All PDFs from PDF Search → Dashboard or Index Activity.
- Ensure Enable Search Integration is on in PDF Search → Settings for normal site search. The shortcode works even when this is off.
- Confirm the PDF is not Excluded.
How do I hide or protect private PDFs from search?
Use Exclude on the PDF (Media Library or PDF Search → Manage PDFs). Excluded PDFs are never indexed and never appear in search, even after Re-index All PDFs. Use Include, then Index, to allow indexing again. To keep a PDF indexed but hidden from logged-out visitors only (e.g., for member resources), use Private PDF Search available on Pro and Agency plans. See Pro plans →
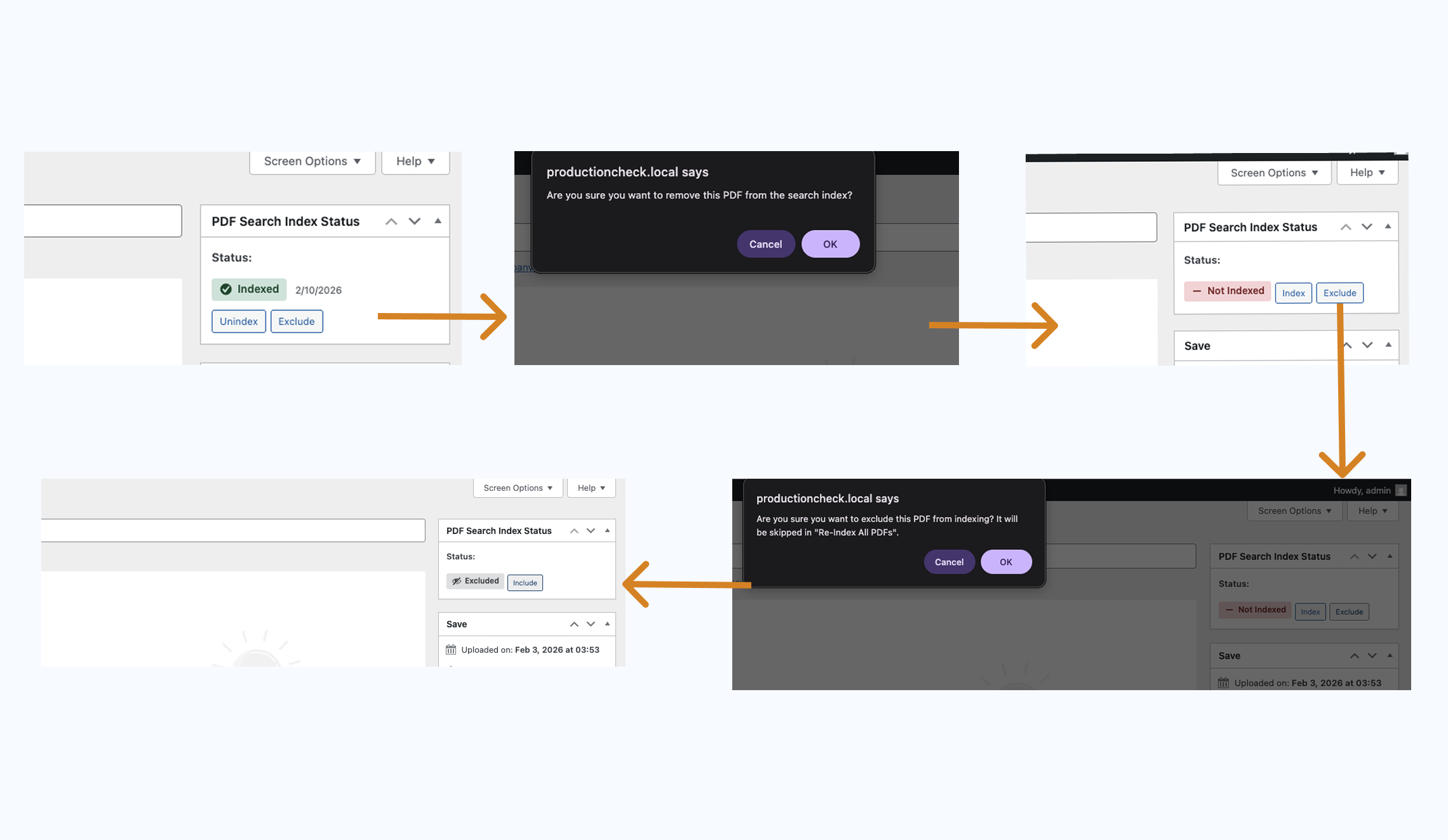
What's the difference between Unindex, Exclude, and Include?
- Unindex – Removes the PDF from search for now. You can index it again anytime (e.g. Index or Re-index All PDFs).
- Exclude – Keeps the PDF out of indexing until you clear it. Re-index All PDFs and bulk Index PDFs skip excluded PDFs. Use for private or sensitive files.
- Include – Clears the exclude flag so the PDF can be indexed again. You still need to run Index or Index PDFs after including.
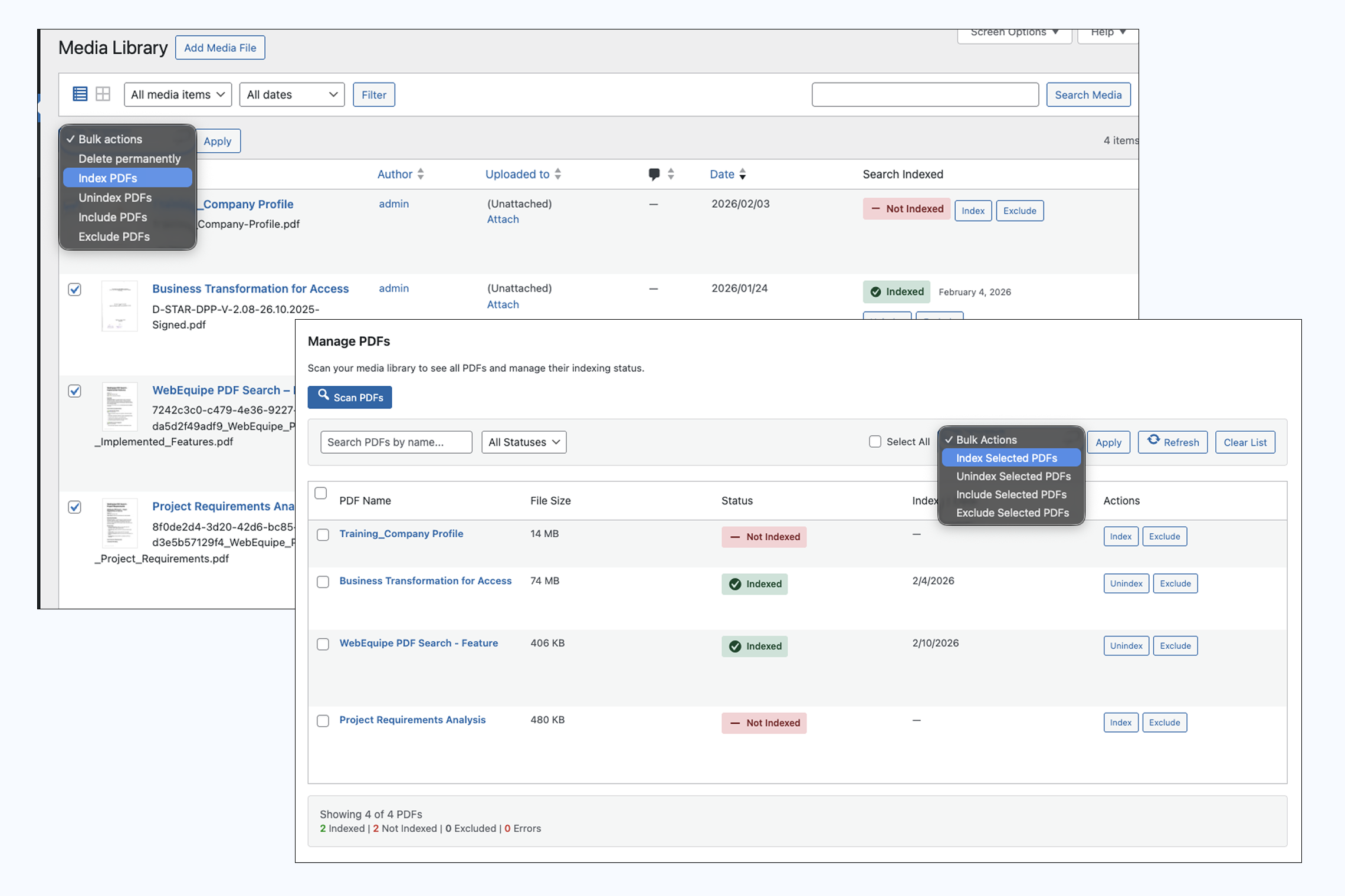
How do I index or re-index many PDFs at once?
Media Library: Select the PDFs → Bulk Actions → "Index PDFs" (or "Unindex"/"Exclude"/"Include") → Apply. Manage PDFs: Go to PDF Search → Manage PDFs → Scan PDFs → select PDFs → choose bulk action → Apply. You can also filter by status (Indexed, Not Indexed, Excluded, Errors).
What's the maximum PDF size?
Default is 50MB. You can raise it (up to 500MB) in PDF Search → Settings → Maximum File Size.
Will it slow down my site?
No. Indexing runs seamlessly in the background (including page-by-page steps for large PDFs) and search queries read directly from the database index. Visitors are not waiting for PDF parsing during live searches.
I upgraded from 1.1.x or earlier. Do I need to re-index?
Yes. Run Re-index All PDFs once after upgrading to 1.2.x so each PDF is stored in the per-page tables and search uses the new index. Until then, a notice may appear on PDF Search admin screens if legacy index data remains.
Password-protected PDFs?
They cannot be indexed because the plugin cannot read their content without the password.
Multisite?
Yes. Each sub-site inside the network maintains its own separate index database.
What languages is the plugin available in?
The plugin interface is translated into English (default), French (fr_FR), German (de_DE), Dutch (nl_NL), and Swedish (sv_SE). Translations load automatically based on your site language (Settings -> General -> Site Language) or your per-user admin language. Help-page documentation currently remains in English.
更新日志:
- Added: Translations for French (fr_FR), German (de_DE), Dutch (nl_NL), and Swedish (sv_SE) covering admin settings, notices, errors, search forms, buttons, and status messages.
- Added: Bundled translations now load for self-hosted/Pro installs via
load_plugin_textdomain()oninit(WordPress 6.7+ safe); JavaScript strings localized throughwp_localize_script(). - Fixed: Indexing error messages (e.g. image-only PDF errors) now display in the active site/admin language on the Dashboard "Needs Attention" panel, Manage PDFs, and Index Activity, instead of the language frozen in the database at index time.
- Changed: New indexing failures store a canonical English source message so the text can be re-translated on display in any language.
- Added: Features admin page (Pro badge in menu) with Free/Starter/Pro/Agency comparison table and How OCR works explainer.
- Changed: Upgrade CTAs in wp-admin use Freemius pricing; Pro launch banner still links to webequipe.com for plan details.
- Version bump for 1.2.3 release.
- Fixed: Dashboard status banner no longer shows "No documents indexed yet" when PDFs are already indexed; counts and last index date use the per-page index tables.
- Fixed: Clear Entire Index now clears per-page files/pages data and related post meta, not only the legacy index table.
- Improved: Manage PDFs — summary metrics, Scan PDFs, last-scanned time, pagination, and clearer status (Indexed, Not Indexed, Processing, Scheduled, Stalled, Error, Excluded).
- Improved: Re-index All PDFs processes every non-excluded PDF (including when Manual Only indexing is selected); large files queue as Scheduled so smaller PDFs are not skipped; progress warns you to keep the page open until finished.
- Improved: Index Activity status for the current run matches Manage PDFs; Refresh added; stale log rows sync when indexing finishes elsewhere.
- Added: Cancel in-flight indexing from Manage PDFs; Resume for stalled jobs; contextual indexing error details (including when Pro OCR may help for scanned or secured PDFs—link to PDF Search → Upgrade to Pro in admin only).
- Added: WebEquipe PDF Search Pro — Native Optical Character Recognition (OCR) for scanned PDFs, Private PDF Search, and Analytics Dashboard. See plans →
- Readme and user-facing docs aligned with 1.2.x admin UI (PDF Search menu, Dashboard, Index Activity, per-page indexing, and current settings).
- Tested up to WordPress 7.0.
- Per-page indexing: file metadata and page content stored in separate tables; large PDFs indexed in background page batches.
- Settings: Max Page Content Length (0 = unlimited per page), Pages Per Batch, Page Index Threshold.
- Search: FULLTEXT/LIKE on page content; one result per PDF with excerpt from the best-matching page.
- Legacy index kept until re-index; run Re-index All PDFs to migrate existing PDFs.
- Index Activity admin page with stats, filterable activity log (one row per indexing run), CSV export, and Re-Index All PDFs.
- Redesigned Dashboard with status banner, metrics, recent activity, shortcodes, and system health sidebar.
- Dismissible Pro launch banner on PDF Search admin pages (early access CTA; not shown after dismiss).
- Image-only PDFs marked Error; mixed PDFs indexed with admin warning.
- Admin safety fix: when new Dashboard/Manage view files are missing in partial installs, plugin now falls back to Settings page instead of showing PHP include warnings.
- Admin UI: moved to top-level PDF Search menu with dedicated Dashboard, Settings, Manage PDFs, and Help pages.
- Branding/UX: consistent page headings and improved Settings page card layout.
- Logging: debug entries are stored via WordPress option/hooks only (no direct filesystem writes), improving compatibility on FTP/SSH filesystem hosts.
- Indexing and debug log: avoid WordPress filesystem/FTP on direct file reads (fewer crashes on bulk re-index with Debug Logging on).
- Processing Timeout now applies per PDF during indexing (typical 30s PHP limit workaround).
- Help: short note on Processing Timeout and host limits.
- Block theme and theme compatibility: PDF meta shows in block themes (e.g. Twenty Twenty-Four/Five) and themes without excerpt block; no duplicate preview or double meta (Astra/Elementor).
- Theme-agnostic CSS: only
webequipe-pdf-*classes; improved preview/meta sizing and alignment. - "Show Author" setting to show uploader name in result meta; Avada compatibility for PDF excerpts.
- Help page and PHPCS/compliance updates.
- Initial release
- Automatic PDF indexing on upload (optional)
- Full-text search in WordPress search and via shortcode
- Settings page: indexing, display options, shortcode, PDF list
- Media Library: index status and per-PDF actions (Index, Unindex, Exclude)
- Bulk actions: Index, Unindex, Include, Exclude
- Exclusion system to keep private or sensitive PDFs out of search
- Background processing for large PDFs
- Template tags and Help documentation
- WordPress Multisite support